Both Hands on the Wheel
A principle for the age of agent-augmented work.
Drafted in conversation with Claude.
The problem we're not talking about
Every team you know is using AI tools daily. Designers, developers, researchers, PMs. The tools work, to some extent at least.
People feel faster. Productivity is, according to everyone, through the roof.
And yet.
Software ship velocity hasn't measurably moved. Document quality hasn't improved at scale. Accessibility hasn't advanced. Software complexity is going up, not down.
Productivity didn't improve, at least not yet.
In 1987, Robert Solow described an earlier version of this exact paradox:
"You can see the computer age everywhere but in the productivity statistics."
We're living through the AI version of the same paradox in real time.
Solow's resolved itself. By the late 1990s, productivity gains arrived, from the work that came after the hype.
Organisations restructured around the computers they had spent a decade buying. Redesigned to match what the new tools could actually do.
The AI version is still in the adoption phase. Whether the gains follow depends on whether the work happens to restructure in the wake of this, and that assumes the economics can be made to make sense; which is a huge assumption considering the current cost of compute.
Agents producing for Agents
A growing share of what AI tools produce is being consumed by other AI tools. Agents writing reports that other agents read and summarise. Summaries cited in further summaries.
Knowledge stores filling with verbose, recursive material that no human ever opens.
It's a familiar pattern from the public internet. The "dead internet theory", that most of the web is now bots talking to bots, overstates the public case. But it understates the enterprise case.
Solow saw it too:
"Newfangled computers were actually at times producing too much information, generating agonisingly detailed reports and printing them on reams of paper."
Internal AI tooling is sliding toward exactly this, faster than most teams realise.
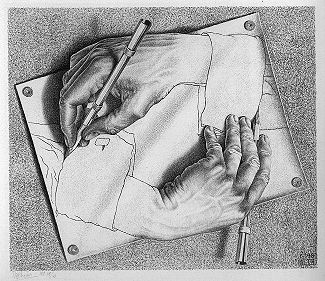
M.C. Escher, Drawing Hands (1948)
 Fair use, https://en.wikipedia.org/w/index.php?curid=3475111
Fair use, https://en.wikipedia.org/w/index.php?curid=3475111
Two hands drawing each other into existence. No third hand anywhere in the picture. No draftsman. The image is perfectly plausible and structurally impossible at the same time.
Of course we know there was a draftsman. Someone who made the system.
They just stepped away. They forgot to set the halting condition.
The principle
Systems augmented by AI agents — design pipelines, knowledge bases, research summarisers, automated reports — only work when humans actively participate at both boundaries.
Upstream:
Humans have to put their genuine thinking somewhere agents can ethically find it. Not in DMs that disappear. Not in personal folders. Not in private drafts. In places the team can read.
Downstream:
Humans have to actively read, retract, and correct what the agents produce. Not as an audience that glances occasionally. As participants who consume the output and feed back into it.
If only one of these happens, the system slides. If neither happens, it collapses.
The Drawing Hands progression
What happens when both hands come off the wheel, in three stages.
Stage 1 — Authorless Authority
The illusion.
Agent output starts looking authored. Symmetrical, polished, plausible. The human starting point gets harder to trace. People stop asking "who wrote this?" because the output is good enough not to need scrutiny.
This is the moment to intervene.
Visible labels on AI-generated content, traceable provenance, an easy way for any team member to retract or correct. All three exist to keep humans in the loop before the loop closes on itself.
Stage 2 — Drawing Hands
The active failure.
Agents reading agents reading agents. Outputs cite outputs. The human is no longer part of the work. They're an audience that occasionally glances at the chart.
The system looks productive because volume keeps going up. Documents reference other documents in long chains. But nothing new is entering from outside.
Two hands drawing each other. No third hand.
I don't have a metric for this but I am seeing it happen.
Jira tickets clearly written by AI, without acknowledgement, without disclosure. Colleagues running Model Context Protocol (MCP) tools to generate insight reports from those same tickets, Agent output becomes Agent input. It's happening in my organisation right now, probably yours too.
By Stage 2, behavioural fixes are too slow. The countermeasures have to become technical — provenance enforcement, generation-depth limits, gating new AI output on whether the previous output was actually read by a person.
The system has to defend itself, because you can no longer rely on humans noticing in time.
Stage 3 — Origin Collapse
The endpoint.
No traceable human starting point for anything in the system. Output is untrustworthy because trust depends on knowing who said something, and no one knows anymore.
A marker for this would be if there was an idea being discussed, from a report, that no one could answer "whose idea was this?"
If you can detect this stage, the people who should have been watching have already left. Detection is itself the failure.
You don't recover from Origin Collapse by adding more checks. You recover by tearing the system down and starting over from human sources.
The scaling problem
The progression above is framed at the level of a single system: a team, an organisation, a knowledge base, a synthesis pipeline.
At that level, you have the levers. You can audit the inputs. You can suspend the outputs. You can tear the system down and start over from human sources. The Stage 3 claim is harsh, but the recovery, if you have the will, is genuinely available.
Society doesn't have those levers in the same way. There's no single system to tear down. The public web isn't an organisation. Wikipedia isn't a department. The information commons is a thousand overlapping systems, each with their own incentives, governance, and rate of decline.
Parts of it have already crossed into Origin Collapse and aren't coming back. Other parts are healthy and probably will remain so. There's no restart move at this scale.
The work is to choose what to protect, build new things in the gaps, and develop the literacy to evaluate what we can't fix.
That's a different kind of work, at a different scale.
What we can do, here and now
This is the work that comes after the hype. These work at different scales: inside an organisation, in publishing economics, in education, in defence of civil liberties.
Cryptographic provenance for digital work.
C2PA, the Coalition for Content Provenance and Authenticity, is an open standard with Adobe, Microsoft, the BBC, the New York Times, the Linux Foundation, and others behind it. It defines a way for digital content to carry a cryptographically signed record of how it was made.
Adobe's user-facing version is branded as Content Credentials. The model side has equivalents: Google DeepMind's SynthID watermarks AI-generated images and audio in ways that survive cropping, compression, and re-encoding.
The point of all of this isn't moral pressure on creators but so a reader looking at an image or document can answer "what made this?" without having to ask the creator.
The limit:
Model-side watermarks can be stripped by motivated bad actors, browser support for displaying credentials is still immature, and adoption across major AI providers is uneven.
What you can do today:
Prefer tools and publishers that support content credentials, and actually look at them when they're there.
Zero-knowledge proofs of provenance.
A zero-knowledge proof is a cryptographic scheme that lets you prove a statement is true without revealing why or how.
Applied to provenance: humans register with a trusted set of verification authorities and get a credential proving "I am one member of this verified-humans group." When they author content, they sign it with a proof linking to "some member of the verified set" without revealing which member.
The reader gets provenance certainty that a real human signed this, without identity disclosure.
This is the cryptographic answer to the anonymity-versus-trust tension. The whistleblower can publish under a verified-human credential and still be anonymous. The journalist can prove their source is real without burning them.
The math is solid: group signatures, ring signatures, anonymous credentials, and ZK-SNARK proofs of set membership exist as working primitives. The engineering is harder. Projects building toward this include Semaphore, Sismo, Polygon ID, World ID, and Privacy Pass; none are consumer-grade yet.
The honest limits are deep though.
Who verifies humans?
The verification authority problem is sociopolitical, not technical. Government IDs exclude undocumented people. Biometric scans alarm civil libertarians. Social-graph systems can be Sybil-attacked (one person registers as many). There's no clean answer.
A verified key can sign AI content.
"A verified human signed this" doesn't mean "a verified human wrote it from scratch." Cryptographic provenance attests to authorship-of-signature, not authorship-of-content. The signature is necessary but not sufficient.
UX is brutal.
Explaining ZKPs to ordinary users is genuinely hard. Adoption tracks the work to make this invisible, and that work isn't done.
The groups who need it most trust verification authorities least.
Dissidents in authoritarian states can't sign up to a verification system run by their own state. The cryptographic anonymity is real; the social trust isn't.
This is the deepest problem and the one that won't be solved by better crypto.
Pay for human authorship.
The free, ad-funded web is what financed the slop machine.
When publishers monetise attention rather than relationship, the incentive bends toward whatever maximises clicks. And AI is the lowest-cost way to maximise clicks. Subscription models reverse the incentive. You pay for the writer, the publication, the institution staking its reputation on what it produces. Books are subscriptions you buy once. Lectures and live performance are subscriptions you pay for in time and attention.
None of this guarantees human authorship by itself; a subscription publication can use AI too. But the relationship between writer and reader survives the AI question in a way that ad-supported attention does not.
The limit:
Paid content creates information-access inequities, and excludes people who can't afford it.
What you can do today:
Subscribe to one publication you'd hate to lose, buy one book a month, go to one talk a quarter.
Disclosure as a professional norm.
Writers, designers, researchers who openly mark which parts of their work used AI, as a professional courtesy.
The reader gets to know how the work was made. "I drafted this in conversation with Claude" is now an acceptable thing to say in professional writing, and saying it changes how the reader interprets the work.
The norm spreads through professional communities: academics, journalists, designers, lawyers. Every time someone discloses without shame, the norm gets stronger.
The limit:
Enforcement is voluntary, bad actors won't disclose, and the social pressure falls hardest on the people most willing to be honest.
What you can do today:
When you publish, disclose. When you read, look for disclosure and quietly prefer the work that has it.
Media literacy as a generational project.
Many people have never had to ask "who wrote this?" because the question wasn't necessary in the environment they grew up in. Content arrived through a feed, attributed to no one in particular, ranked by an algorithm.
The skill of source-checking is a muscle that was previously built implicitly. You knew which newspaper was reliable, which TV channel had standards, who had a byline. That implicit teaching is gone. Now the skill has to be taught explicitly, often to adults, and the institutions that would teach it are themselves under pressure.
The limit:
This is a slow move, the hardest to fund, and the people most affected are often the least equipped to learn the skill from scratch.
What you can do today:
Model the question "who wrote this?" out loud, at work, in conversation, with your kids.
Make the asking visible.
Refuse to share things that don't have it.
For everyone working with AI agents
You are not an audience. You are a participant.
When you produce thinking, put it where it can be found.
When the system produces output in your name, read it. Retract what's wrong.
Correct what's drifted. Cite what's useful.
Both hands. Otherwise it's just a drawing, drawing itself.
References
- The Solow paradox. Robert M. Solow, "We'd Better Watch Out," New York Times Book Review, July 12, 1987, p. 36. Reviewing Stephen S. Cohen and John Zysman, Manufacturing Matters: The Myth of the Post-Industrial Economy. Broader background: Productivity paradox, Wikipedia.
- METR — AI's effect on developer productivity (July 2025). A randomised study of 16 experienced open-source developers found AI use slowed task completion by 19%, despite developers expecting it to speed them up by 24% — and continuing to believe afterwards that it had sped them up by 20%. Measuring the impact of early-2025 AI on experienced open-source developer productivity, METR.
- DORA — 2024 State of DevOps Report. AI adoption significantly increases individual productivity, flow, and job satisfaction while negatively impacting team-level software delivery throughput and stability. dora.dev.
- WebAIM Million — 2026 report. Of the top one million home pages, 95.9% have detectable WCAG 2 failures — up from 94.8% in 2025, reversing six years of small improvements. The WebAIM Million.
- AI-induced technical debt. Empirical analyses of large codebases — GitClear's review of 153 million changed lines and recent arXiv work on AI-assisted programming — find AI assistants accelerate code addition while increasing technical debt, with the debt remaining rather than being removed. Debt Behind the AI Boom, arXiv 2026.
- AI compute economics — May 2026. Microsoft scaled back internal Claude Code licenses after token costs ran ahead of staff salaries; Uber burnt its entire 2026 AI coding budget in four months; an Nvidia executive: "For my team, the cost of compute is far beyond the costs of the employees." Microsoft reports are exposing AI's real cost problem, Fortune, May 2026.
- Dead internet theory. Dead Internet theory, Wikipedia.
- M.C. Escher, Drawing Hands (1948). Lithograph. Drawing Hands, Wikipedia.
- C2PA — Coalition for Content Provenance and Authenticity. c2pa.org. Adobe's user-facing implementation: Content Credentials.
- SynthID. Google DeepMind's watermarking system for AI-generated content. DeepMind — SynthID.
- Zero-knowledge proofs. Originating paper: Goldwasser, Micali, and Rackoff, "The Knowledge Complexity of Interactive Proof Systems," Proceedings of the 17th ACM Symposium on Theory of Computing, 1985. Overview: Zero-knowledge proof, Wikipedia.
- Ring signatures, group signatures, anonymous credentials, zk-SNARKs. Entry points: Ring signature, Group signature, Non-interactive zero-knowledge proof, Wikipedia.
- Sybil attacks. Originating paper: John R. Douceur, "The Sybil Attack," International Workshop on Peer-to-Peer Systems (IPTPS), 2002. Overview: Sybil attack, Wikipedia.
- Semaphore. A zero-knowledge group-membership and signalling protocol from Privacy & Scaling Explorations. semaphore.pse.dev.
- Sismo. A ZK-based identity and selective-disclosure project; the team has shifted from ZK Badges to Sismo Connect, an SSO-style flow that aggregates and selectively discloses verifiable credentials. Background: Sismo blog.
- Polygon ID, now Privado ID. Open-source middleware for privacy-preserving credentials. privado.id.
- World ID. Worldcoin's proof-of-personhood credential. world.org/world-id.
- Privacy Pass. Originally a browser extension for anonymous authentication; now also an active IETF standards effort. Project: privacypass.github.io. Standards: IETF Privacy Pass WG.